World Wide Web is an easy web challenge that can be solved using different techniques. I will describe my approach to solve this challenge using wget and its --mirror option to download the website, together with the common text manipulation tools and visual inspection for finding the flag.
Challenge info
- Event: CSAW Quals 2022
- Category: Web
- Points: 54
Writeup
Opening the link leads to a page that says “Please help me find my missing stuff . :(“, where stuff is a hyperlink to /stuff.
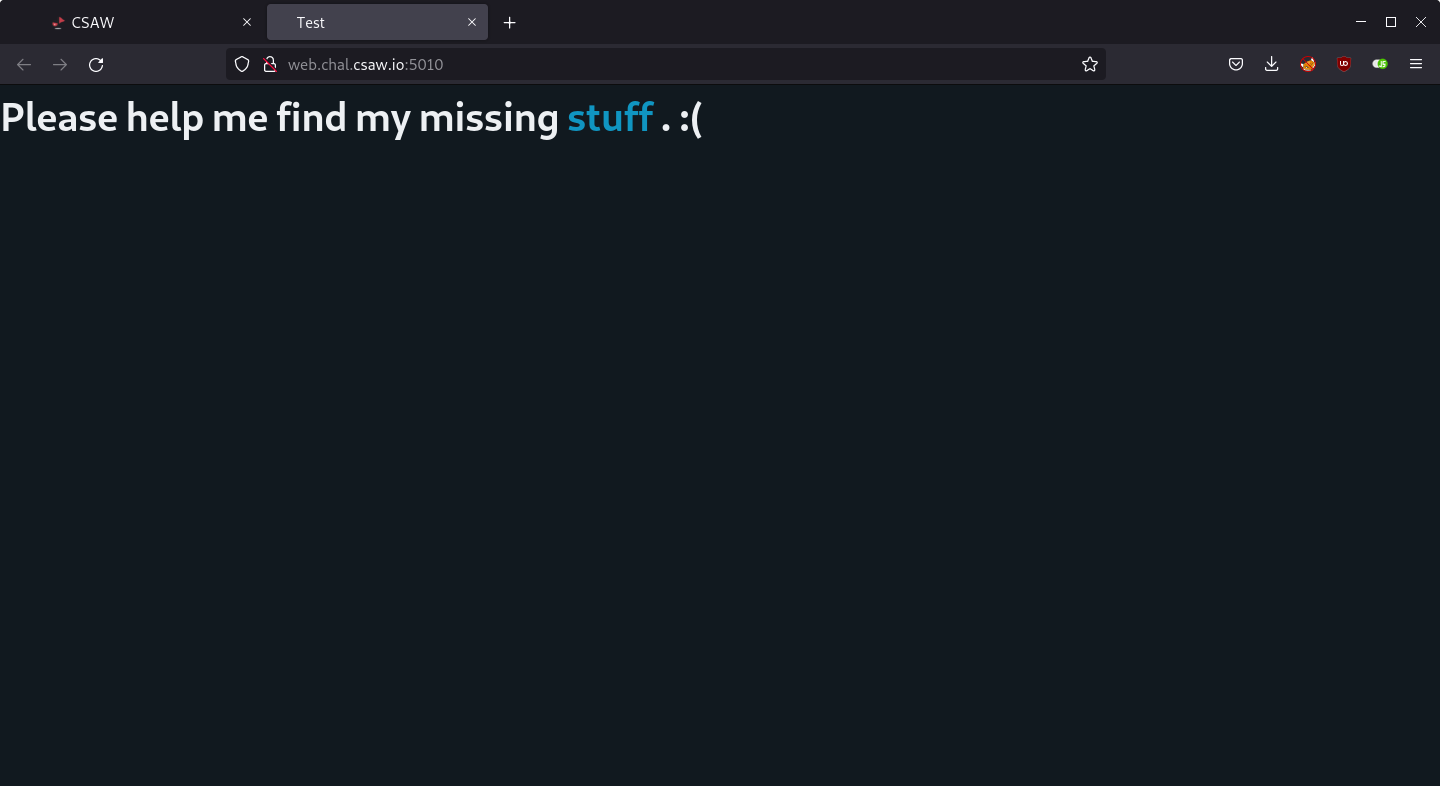
There is nothing interesting in the page source either.

I followed that link and I could see lots of words on the next page.
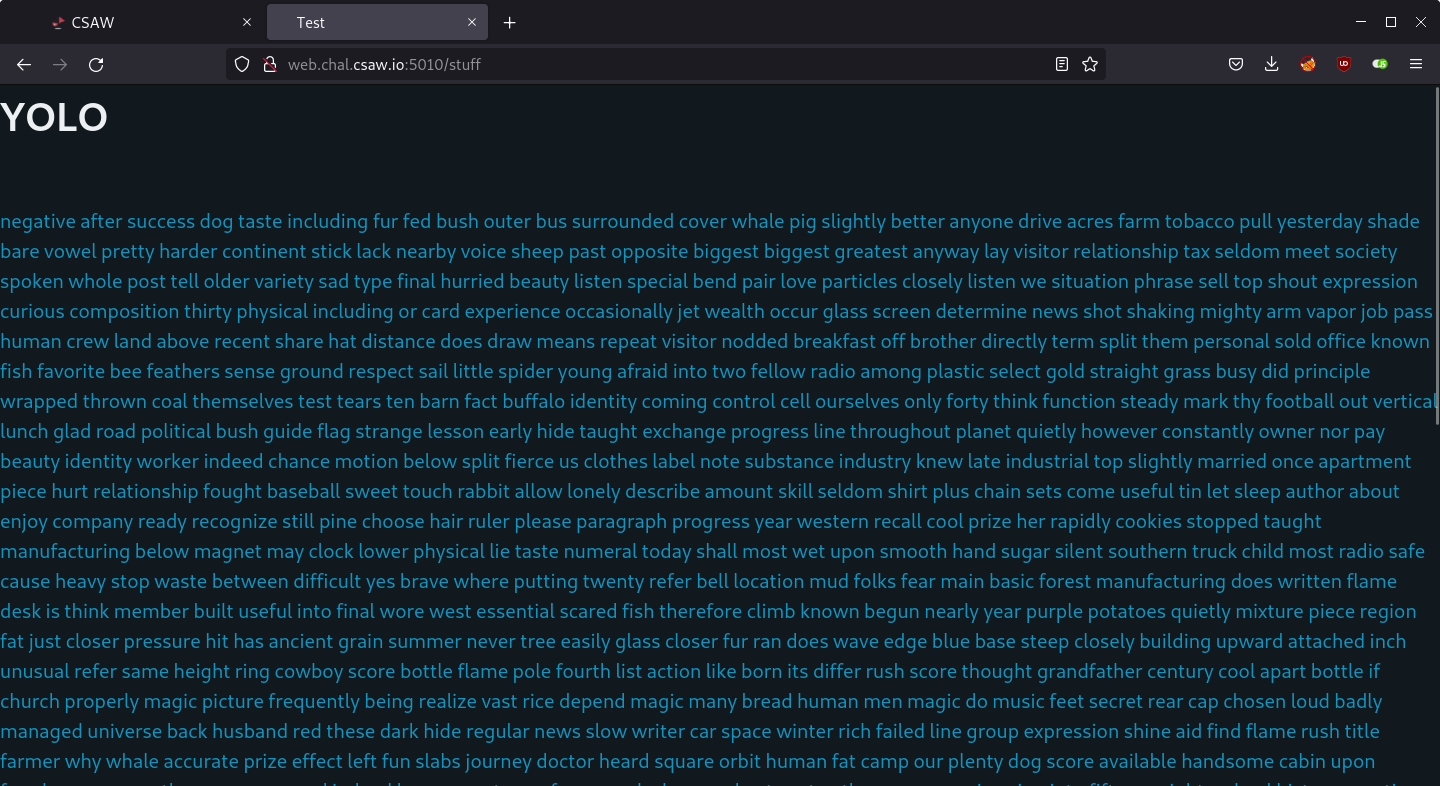
Each word is inside an anchor tag but they have no href attribute, so they are actually not hyperlinks. It looked like I am supposed to find the “real” link that leads somewhere, so I searched for a href in the page source and I found a link to /tribe.
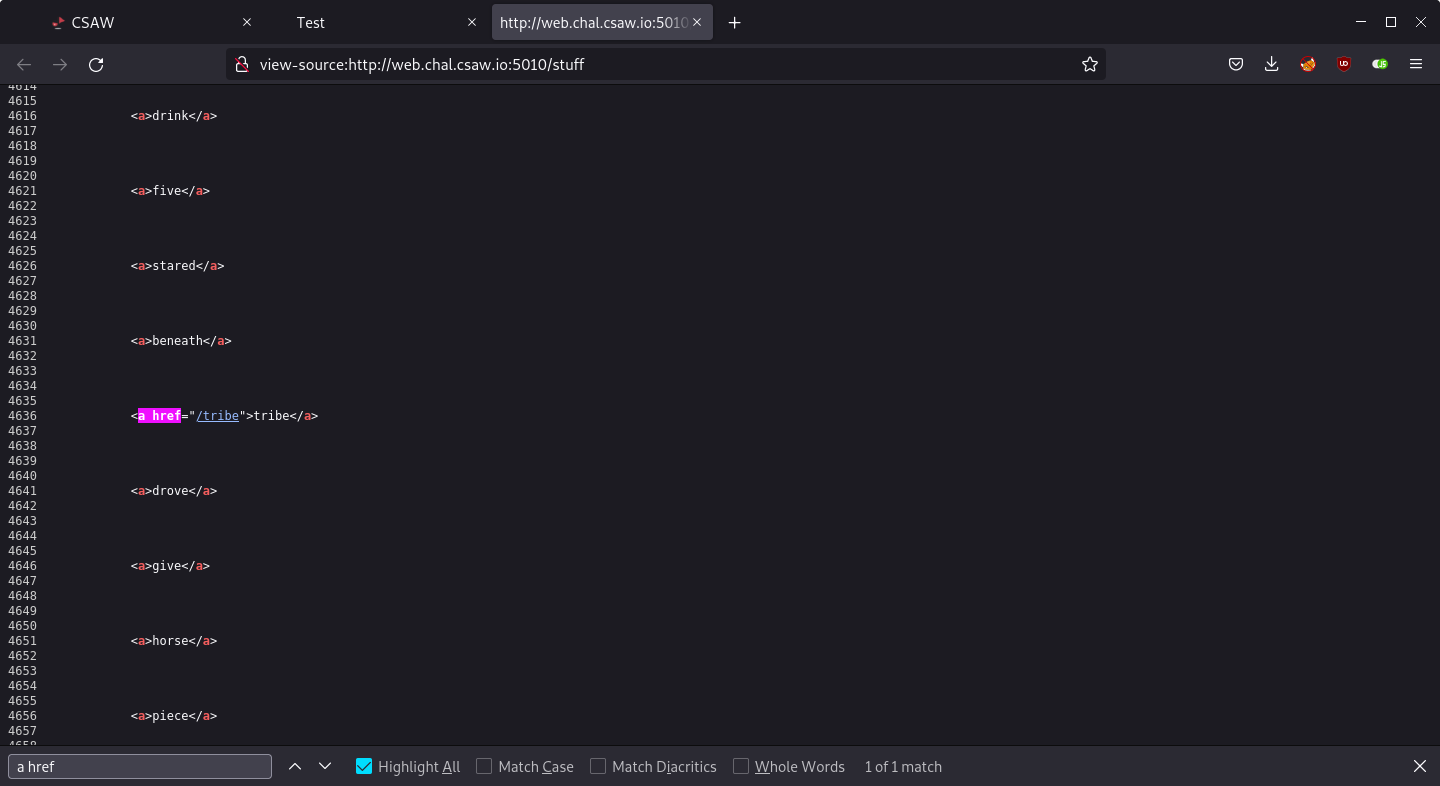
Another page, another set of words. I searched for a href again and found /grain.
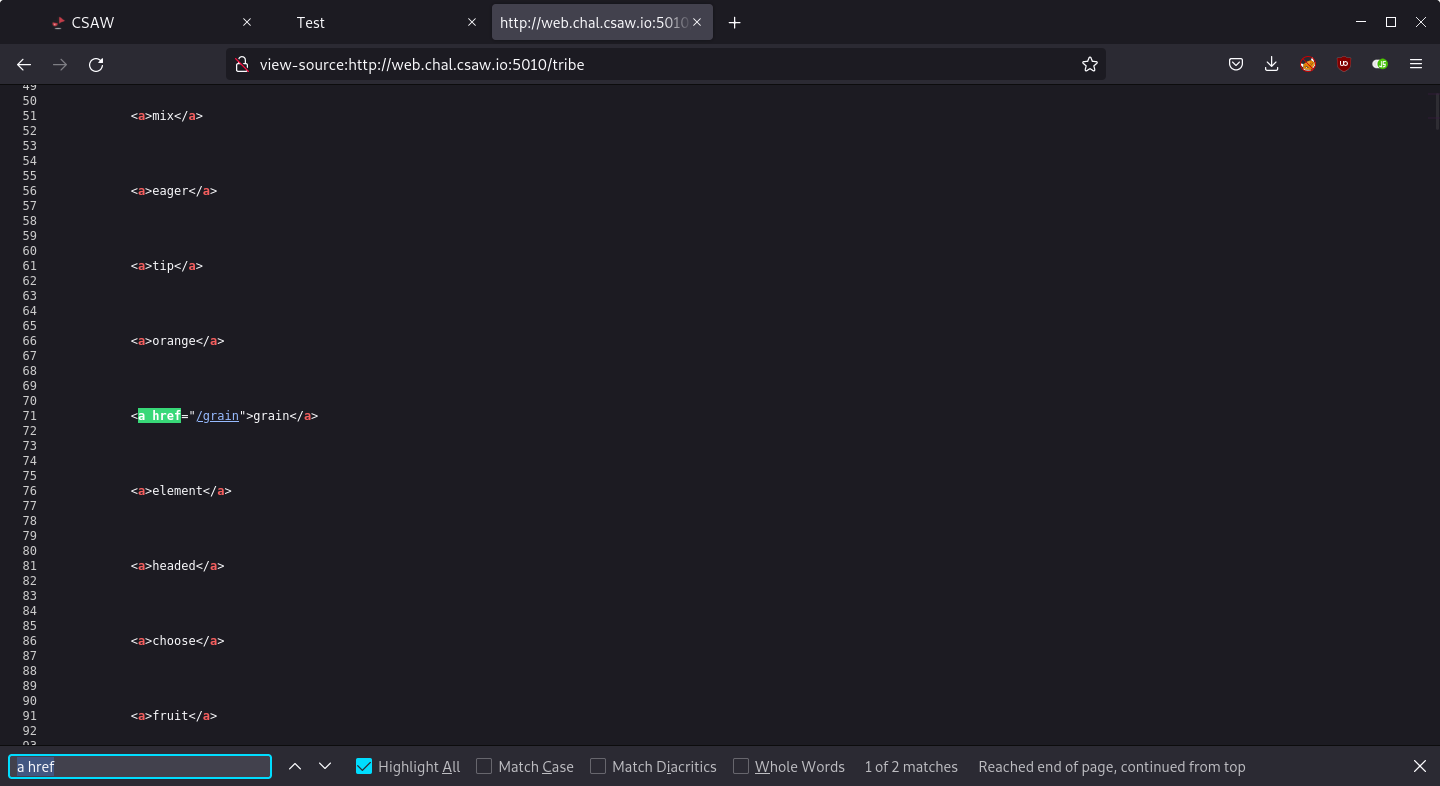
/grain leads to /design and so on.
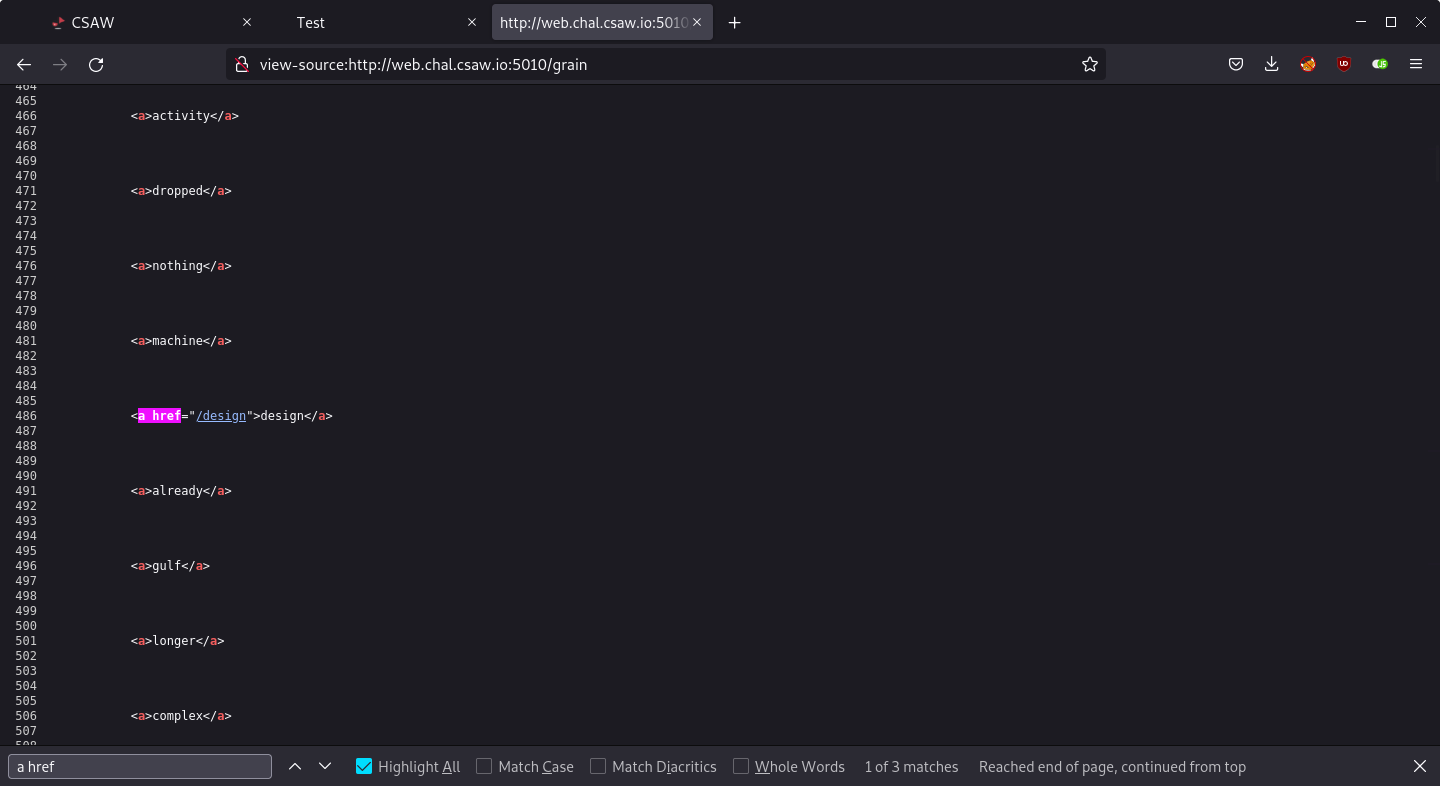
At this point it’s clear that the automation is necessary. Writing a Python script to follow these links is a good idea, but I decided to let wget do this task.
I ran wget --mirror http://web.chal.csaw.io:5010 and quickly I had the whole website inside one directory, ready to be searched.
web.chal.csaw.io:5010/
├── activity
├── anyone
├── anything
...
├── index.html
├── robots.txt
...
├── whose
├── wise
└── yesterday
0 directories, 99 files
Before thinking of running grep -r "CTF", remember the note from the challenge description:
The flag doesn’t have a wrapper. It needs to be wrapped with curly brackets and please put
CTFin front of the curly brackets.
Since I had 99 text files, I played with the text manipulation tools and got this:
cat * | awk '{$1=$1;print length, $0}' | sort -n | cut -d' ' -f2- | uniq
This command trims leading and trailing whitespace from every line, sorts the lines by length and removes the duplicates. What is left is convenient for visual inspection.
...
<a href="/breakfast">breakfast</a>
<a href="/dangerous">dangerous</a>
<a href="/yesterday">yesterday</a>
</html>CTF{w0rdS_4R3_4mAz1nG_r1ght}
<a href="/everywhere">everywhere</a>
<a href="/satellites">satellites</a>
<a href="/television">television</a>
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<h1>Please help me find my missing <a href="/stuff"> stuff </a>. :( </h1>
<link rel="stylesheet" href="https://unpkg.com/@picocss/pico@latest/css/pico.min.css">
Quickly, we see our flag: CTF{w0rdS_4R3_4mAz1nG_r1ght}
Also, it does have a wrapper.

More on text manipulation
Let’s talk about how I built that command.
I started by printing all the files from /web.chal.csaw.io:5010 directory using cat. Although we commonly use cat for printing the file contents, it’s actually short for “concatenate” and it can be used for concatenating multiple files. For example: cat a.txt b.txt outputs contents of a.txt and b.txt. I used * to output everything.
cat *
...
<a>zipper</a>
<a>metal</a>
<a>crop</a>
</p>
</body>
</html>
This output looks terrible. It is no surprise since this is HTML code so the lines have lots of leading whitespace.
I used awk to remove the leading and trailing whitespace (stackoverflow thread).
cat * | awk '{$1=$1;print}'
<a>zipper</a>
<a>metal</a>
<a>crop</a>
</p>
</body>
</html>
If the flag is written somewhere in the code, I expected it to be among the longer lines since most lines are just words wrapped inside anchor tags (e.g. <a>metal</a>).
I changed awk to print the line length, and used sort -n to sort the lines according to string numerical value, which would sort the lines by length.
cat * | awk '{$1=$1;print length, $0}' | sort -n
...
86 <link rel="stylesheet" href="https://unpkg.com/@picocss/pico@latest/css/pico.min.css">
86 <link rel="stylesheet" href="https://unpkg.com/@picocss/pico@latest/css/pico.min.css">
86 <link rel="stylesheet" href="https://unpkg.com/@picocss/pico@latest/css/pico.min.css">
86 <link rel="stylesheet" href="https://unpkg.com/@picocss/pico@latest/css/pico.min.css">
86 <link rel="stylesheet" href="https://unpkg.com/@picocss/pico@latest/css/pico.min.css">
86 <link rel="stylesheet" href="https://unpkg.com/@picocss/pico@latest/css/pico.min.css">
At the end of the output, we can see the longest lines in the directory followed by a number that represents their length. I removed that number using cut -d' ' -f2-, where -d' ' sets the delimiter to a space, and -f2- tells it to print fields starting from the second field until the end (different from -f2 which prints only the second field).
The next logical step would be to filter all those duplicate lines, which is done using uniq.
And that’s how I built this command.
cat * | awk '{$1=$1;print length, $0}' | sort -n | cut -d' ' -f2- | uniq
...
<a href="/yesterday">yesterday</a>
</html>CTF{w0rdS_4R3_4mAz1nG_r1ght}
<a href="/everywhere">everywhere</a>
...
Conclusion
World Wide Web is an easy challenge that was likely meant to be solved using Python and requests module, but wget --mirror also comes in handy since it’s just a static website. The flag wrapper was probably left there by accident, but now you know some text manipulation tricks cooler than grep -r "CTF"! 🎉
It was an easy challenge for warming up for the remaining CSAW challenges, and it’s also good for practicing your scripting skills.
That’s all for this short writeup! Thank you for reading and have a great day.